
使用 AWS S3 存储桶中导出的录音
设置 AWS S3 记录批量操作集成后,您可以将 Genesys Cloud 中的录音批量导出到您的 AWS S3 存储桶。 此导出可以通过 QM 策略自动执行,也可以通过调用录制批量操作 API 显式执行。
本文详细介绍了导出到您的 AWS S3 存储桶的内容。
AWS S3 存储桶内容
录制文件导出到 AWS S3 存储桶到具有以下结构的文件夹中:
s3://{bucket}/{organizationId}/year={year}/{month={month}/day={day}/hour={hourOfDay}/conversation_id={conversationId}/
| 占位符 | 描述 |
|---|---|
| {存储桶} | S3 存储桶名称。 |
| {组织 ID} | 组织 ID。 |
| {年} | 对话开始的那一年。 |
| {月} | 对话开始的月份(以数字表示)。 |
| {day} | 对话开始的那一天。 |
| {HourofDay} |
对话开始的那一小时。 |
| {对话 ID} |
会话 ID。 |
该文件夹包含对话期间保留的所有录音文件。 每个录制文件都有一个录音,文件名是录音 ID。
每个录制文件都有相应的 JSON 元数据文件。 JSON 元数据文件名以 “_metadata.json” 为后缀。
元数据可用于搜索导出的录音。 有关更多信息,请参阅 A thena+Glue 示例(录音搜索服务示例)。
元数据文件采用 JSON 格式,架构如下。
{
“$schema”: “http://json-schema.org/draft-04/schema#”,
“类型”:“对象”,
“properties”: {
“mediaType”: {
“描述”:“媒体类型(通话、聊天、电子邮件、消息、屏幕之一)”,
“type”: “string”
},
“mediaSubtype”: {
“描述”:“录音的子类型(中继、站台、咨询、屏幕之一)”,
“type”: “string”
},
“mediaSubject”: {
“描述”:“录音的主题”,
“type”: “string”
},
“provider”: {
“描述”:“录音提供商的类型,例如 edge”,
“type”: “string”
},
“userIds”: {
“描述”:“用户列表”
“类型”:“数组”,
“items”: [
{
“type”: “string”
}
]
},
“startTime”: {
“描述”:“录音开始时间”,
“type”: “string”
},
“endTime”: {
“描述”:“录音结束时间”,
“type”: “string”
},
“durationMs”: {
“描述”:“录音时长”,
“type”: “integer”
},
“初始方向”:{
“描述”:“对话的初始方向(入站/出站)”,
“type”: “string”
},
“aniNormalized”: {
“描述”:“ANI”,
“type”: “string”
},
“aniDisplayable”:{
“描述”:“可显示形式的 ANI”,
“type”: “string”
},
“dnisNormalized”: {
“描述”:“DNIS”,
“type”: “string”
},
“dnisDisplayable”:{
“描述”:“可显示形式的 DNIS”,
“type”: “string”
},
“queueIds”: {
“描述”:“录制队列 ID 列表”,
“类型”:“数组”,
“items”: [
{
“type”: “string”
}
]
},
“wrapupCodes”: {
“描述”:“对话总结代码”,
“类型”:“数组”,
“items”: [
{
“type”: “string”
}
]
},
“organizationId”: {
“描述”:“对话的唯一ID”,
“type”: “string”
},
“conversationId”: {
“描述”:“与对话关联的唯一 ID”,
“type”: “string”
},
“conversationStartTime”: {
“描述”:“对话开始时间”,
“type”: “string”
},
“conversationEndTime”: {
“描述”:“对话结束时间”,
“type”: “string”
},
“recordingId”: {
“描述”:“录音的唯一ID”,
“type”: “string”
},
“filePath”: {
“描述”:“录音的原始路径”,
“type”: “string”
},
“fileSize”: {
“描述”:“录音文件大小”
“type”: “integer”
},
“messageType”: {
“描述”:“消息来源平台的类型,例如 SMS、Twitter、Line、Facebook、WhatsApp、WebMessaging、Open、Instagram”,
“type”: “string”
},
“languageIds”: {
“描述”:“语言标识符”,
“类型”:“数组”,
“items”: [
{
“type”: “string”
}
]
},
“screenInformation”: {
“描述”:“屏幕具体信息,包括屏幕ID,X和Y位置,分辨率信息”,
“type”: “object”
}
},
“required”: [
“mediaType”,
“提供者”,
“startTime”,
“endTime”,
“durationMs”,
“organizationId”,
“conversationId”,
“conversationStartTime”,
“conversationEndTime”,
“recordingId”,
“filePath”,
“fileSize”
]
}
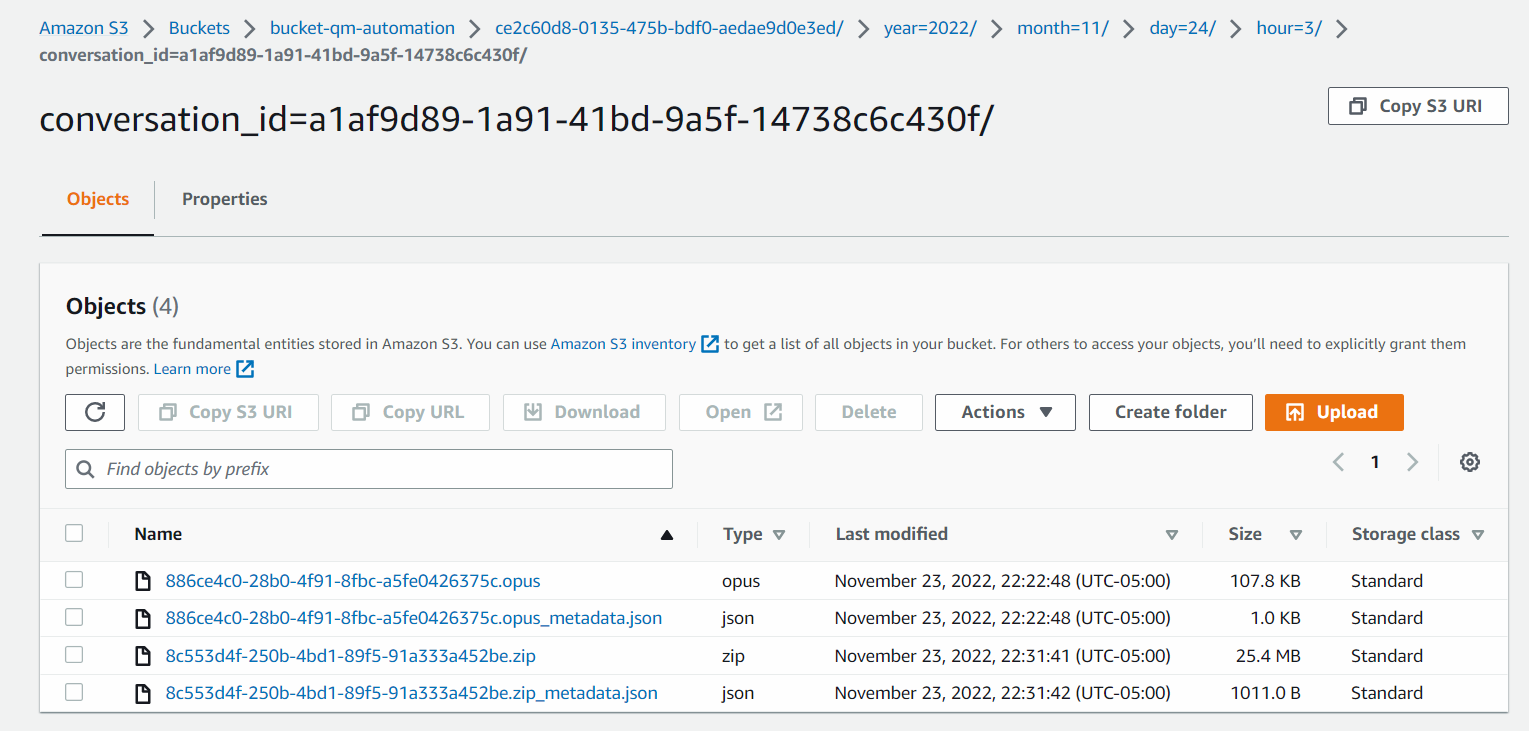
例如,启用屏幕录制的通话对话可能包含以下文件夹内容。
在下图中,.opus 文件是录音文件,.zip 文件包含屏幕录制文件,.json 文件是与相应媒体文件关联的 JSON 元数据。
点击图片放大。
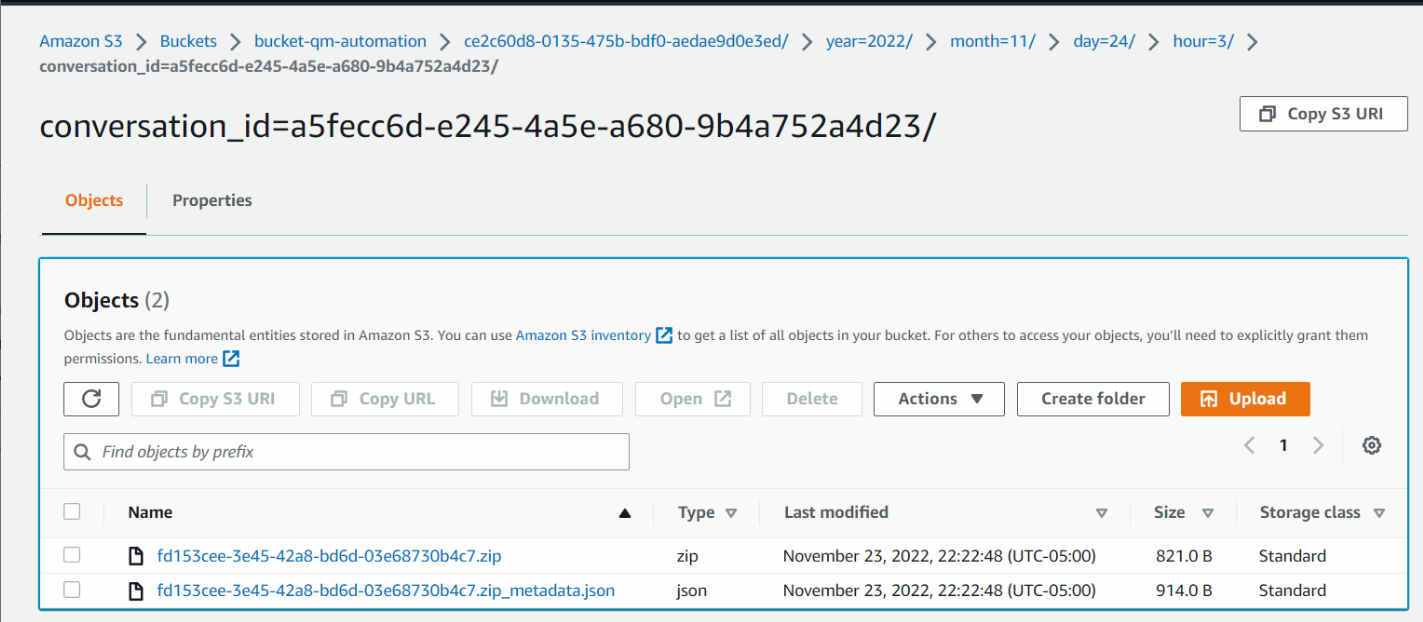
数字对话可能包含以下文件夹内容。
在下图中,.zip 文件包含数字录制文件,而.json 文件是相应的 JSON 文件。
点击图片放大。
加密
您的 S3 存储桶已经配置了 AWS S3 服务器端加密 (SSE)。 它可能已使用由 Amazon S3 托管的加密密钥 (SSE-S3) 启用,也可能是使用 AWS 托管密钥或客户提供的来自 AWS 密钥管理服务 (SSE-KMS) 的密钥启用的。
AWS S3 服务器端加密 (SSE) 保护 S3 存储桶中的静态录制文件。 当从存储桶检索文件时,AWS 会自动解密文件内容。
如果您的系统还包含已启用的录制导出加密,则在从 S3 存储桶检索文件后,您必须自己解密文件内容。