
虚拟代理槽创作建议和限制
当您启用虚拟代理时,您可以使用它来配置 AI 驱动的插槽。在使用虚拟代理配置插槽和插槽类型之前,请查看 Genesys 开发人员针对大型语言模型 (LLM) 插槽推荐的限制、注意事项和提示。下表定义了虚拟代理可用的插槽类型。
| 插槽类型 | 描述 | 示例 |
|---|---|---|
| 数字序列 |
机器人参与者提供的具有固定长度的数字序列。 |
|
| 字母数字组合 |
机器人参与者提供的具有固定长度的字母数字序列。 |
|
| 自由形式 |
机器人参与者提供的具有给定描述的自由形式序列。 |
|
以下部分描述了插槽限制、有关这些插槽如何处理机器人参与者的明确确认和否定的信息以及具体示例。
数字槽
当您希望机器人仅将数字字符视为提取序列的一部分时,请使用此插槽类型。该机器人无法识别其他字符。
- 超过设置的 maxLength 值的实体将不被接受。例如,如果实体值为“123456”且 maxLength 设置为 7,而客户说“78”,那么由于新提取的实体为“12345678”且长度现在为 8,因此机器人会将新实体视为 noMatch,并将余数保留为“123456”。
- 纠正不明确的情况或位于提取实体中间部分的情况。在以下示例中,之前提取的实体是 1299554464。
工作修正示例:- “最后两位数字从 64 变为 62 不变”
- “最后两位数字应该是 62”
非工作修正示例:
-
- “No 62.”LLM 无法确定要改变什么。
- “不,我的意思是62。”LLM 无法确定要改变什么。
- “将 55 改为 44。”由于该条目位于实体的中间,因此 LLM 很难确定。
- “实体应该以 5 开头。”LLM 可能会在开头添加 5 或者可能会按预期将“1299554464”更正为“5299554464”。
-
- LLM 不会因为数值较大而出现问题;但是,这样做会增加更困难的纠正的可能性。数值越大,其开始处或中间位置越难纠正。由于这个限制,Genesys 建议使用多槽性质,因此如果提取了信用卡号,则要求以 4 位数字的块形式提供数据。任何错误都发生在最后四位数字内,这使得更易于纠正。
效果良好的案例有:
- 简单提取所有长度的数字。例如,“我的信用卡号是 0123456789012232。”
- 使用词汇格式的数字进行多次数字提取。例如:
- 參與者:“我的卡以 0011 开头”机器人:“我目前得到0011,请继续。”
- 參與者:“那么7831”机器人:“我目前得到 0011 7831,请继续。”
- 參與者:“七一双哦”机器人:“我目前得到 0011 7831 7100,请继续。”
- 參與者:“终于,3333”机器人:“我得到的是 0011 7831 7100 3333,正确吗?”
- 明确的更正;例如“将最后两位数字从 84 更改为 82”。
- LLM 将“Double”视为其后的数字之二;例如,double 2 = 22。ASR 应该首先将此响应转换为 22。“三倍”/“高倍”是该数字的三位,“四倍”是四位。
- LLM 在预期的情况下将“哦”视为“0”,而不是在意外的情况下,例如“哦,对不起,我的意思是”。
字母数字槽
当参与者使用拼音字母时,使用此插槽类型在提取过程中提供提示;例如,北约音标字母。例如,用户可以说“a for alpha”,提取的字符就是“A”。
- 超过设置的 maxLength 值的实体将不被接受。例如,如果实体值为“A12345”,maxLength 设置为 7,而客户说“67”,那么由于新提取的实体为“A1234567”,长度现在为 8,因此机器人将新实体视为 noMatch 并保留实体“A12345”。
- 多个回合中重复的字符。如果在第一次轮次中,提取的实体是“AB78G”,而在下一次轮次中客户以另一个“g”开始,那么 LLM 可能会错误地返回“AB78G”而不是“AB78GG”。
- 含糊不清的修正。例如,“不,我说的是 AZ。”如果在第一次轮到客户说“A 代表苹果,C 代表 72”,而提取出来的结果是“AC72”,那么就可能会发生模棱两可的纠正;在下一次轮到他们时,他们可能会做出困难的纠正,例如“不,我说的是 AZ”。
- LLM 不会因为字母数字值较大而出现问题;但是,这样做会增加更难以纠正的可能性。数值越大,其开始处或中间位置越难纠正。由于这个限制,Genesys 建议使用多槽性质,因此如果提取了护照号码,则要求以 3 个字符的块形式输入数据。任何错误都发生在最后3位数字内,这使得更易于纠正。
效果良好的案例有:
- 提取所有长度的字母数字,包括字母的拼音、简单陈述的字母和数字。例如,“我的护照号码是 a 代表苹果、b 代表 beta、c 代表查理、d 代表 8909。”
- 使用词汇格式的数字进行多次字母数字提取,例如:
- 參與者:“我的会员号码以 AB11 开头”机器人:“我目前已经得到 AB11,请继续。”
- 參與者:“那么 c 代表 charlie,z 代表 zeta”机器人:“我目前已经获得了 AB11 CZ,请继续。”
- 参与者:“beta alpha”机器人:“我目前已获得 AB11 CZ BA,请继续。”
- 參與者:“终于99了”机器人:“我得到了 AB11 CZ BA 99,对吗?”
- 明确的更正。例如,“不,zeta 的最后一个字母应该是 Z 而不是 c。”
- LLM 将“Double”视为其后的数字之二;例如,double 2 = 22。ASR 应该首先将此响应转换为 22。“三倍”/“高倍”是该数字的三位,“四倍”是四位。
- LLM 在预期的情况下将“哦”视为“0”,而不是在意外的情况下,例如“哦,对不起,我的意思是”。
自由形式插槽
当您希望机器人识别要捕获的实体的文本描述时,请使用这些插槽。例如,包含街道名称、城市和 PIN 码的地址。
- 地址
- 符合特定国家标准的地址格式。机器人参与者必须依赖您提供的描述来确保正确的格式。
- 套管:正确的大小写通常是正确的;但是,提取的实体有时可能会全部返回小写或全部大写。
- 电子邮件
- 在多轮对话中自定义域名识别不正确。当一次性提供电子邮件时,会发生更常见、更准确的回报。
- ASR 转录无法转换破折号、点和下划线的情况。
- 名字
- 拼写长名字时缺少或重新排列字符。
每次调用后的模型输出包含两部分:提取的实体和一个布尔值,表示提取是否完成,实体检测状态是进行中还是已完成。对于自由形式,机器人使用提供的描述。
- 模型使用描述来判断实体是否被捕获或者描述中提到的部分是否缺失。理想情况下,描述应该包含实体的内容以及实体必须包含的其他子实体或部分。
- 也可以跳过。如果客户明确地说出类似的话: “我完成了,就是这样,这就是全部,我没有,我不知道”等等,提取状态变为已完成,并根据描述覆盖子实体集合。
自由形式插槽示例:机器人能够正确判断实体检测状态的情况
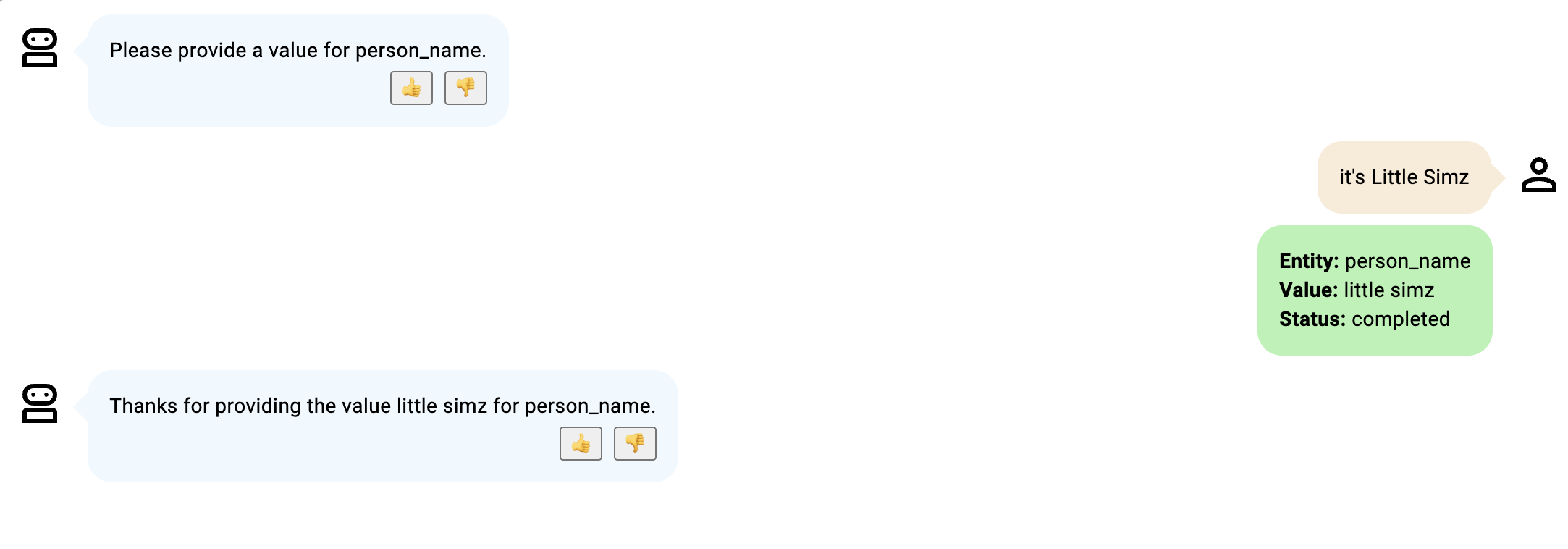
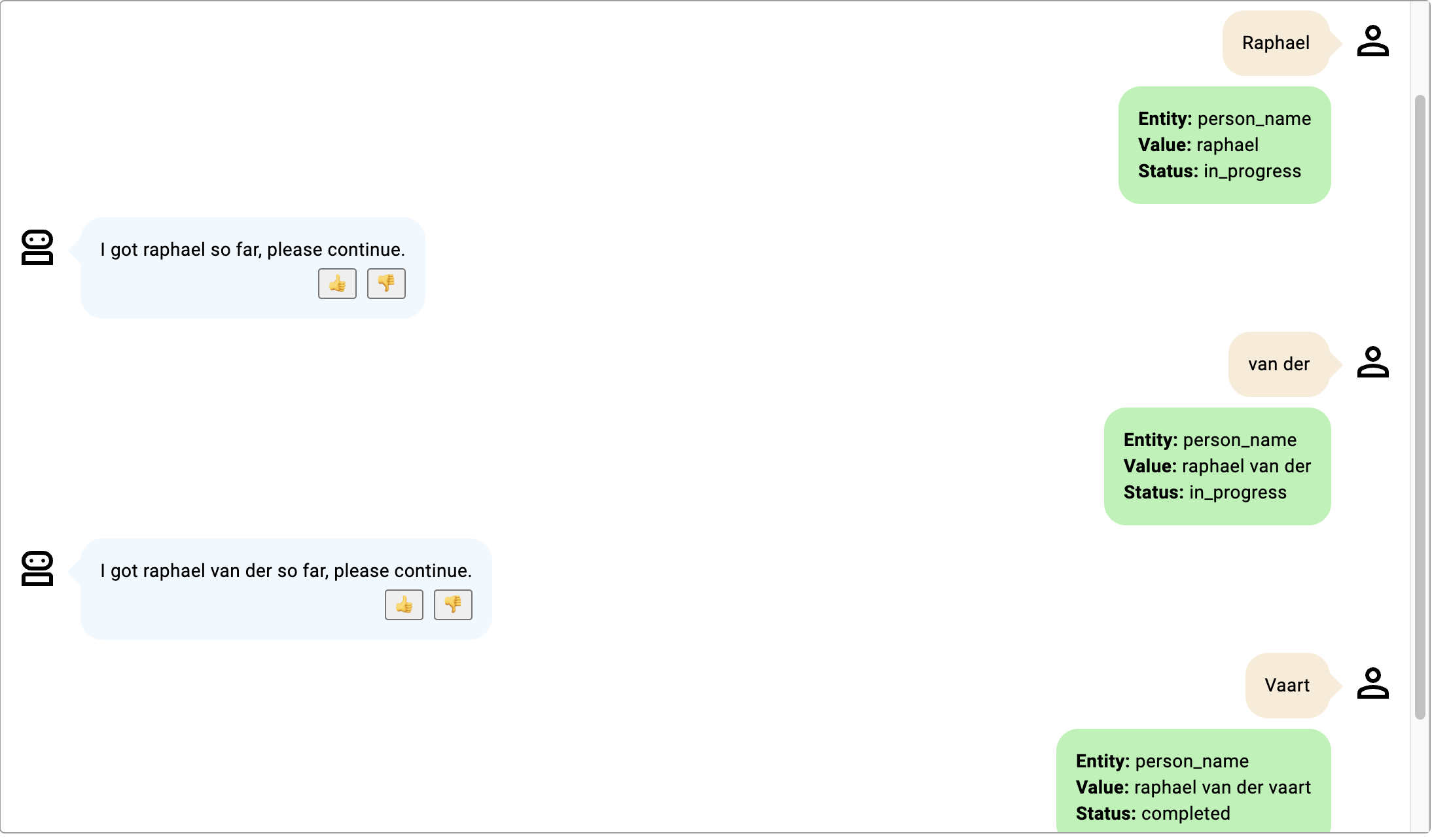
在这些例子中,插槽是 person_name,用于描述一个人的名字和姓氏。
- 机器人参与者具体提到了提供实体的哪一部分。
点击图片放大。
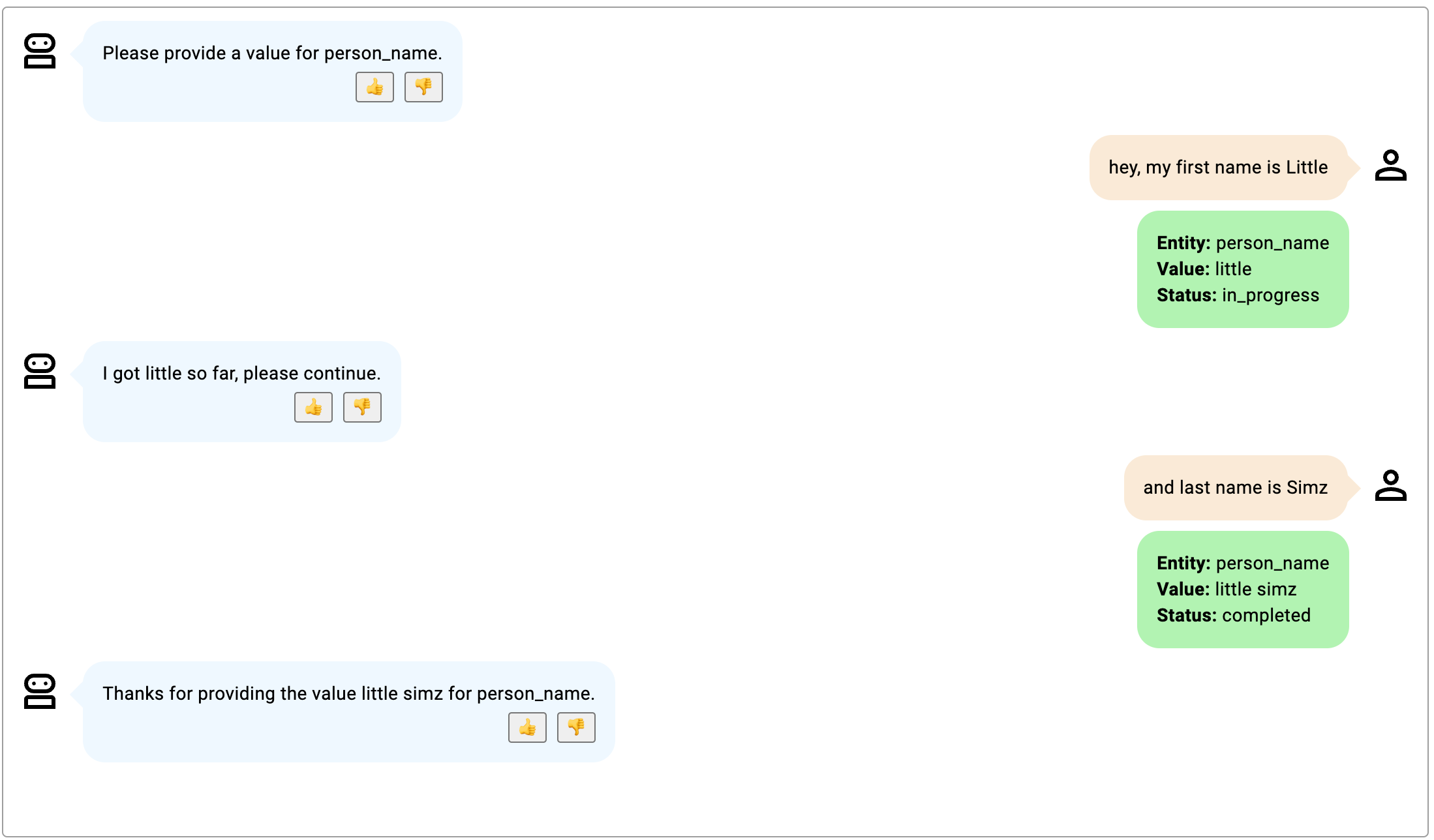
- 机器人参与者仅在初始轮中提到提供了姓名的哪一部分;该模型假设机器人参与者提供的下一个子实体是姓氏。
点击图片放大。
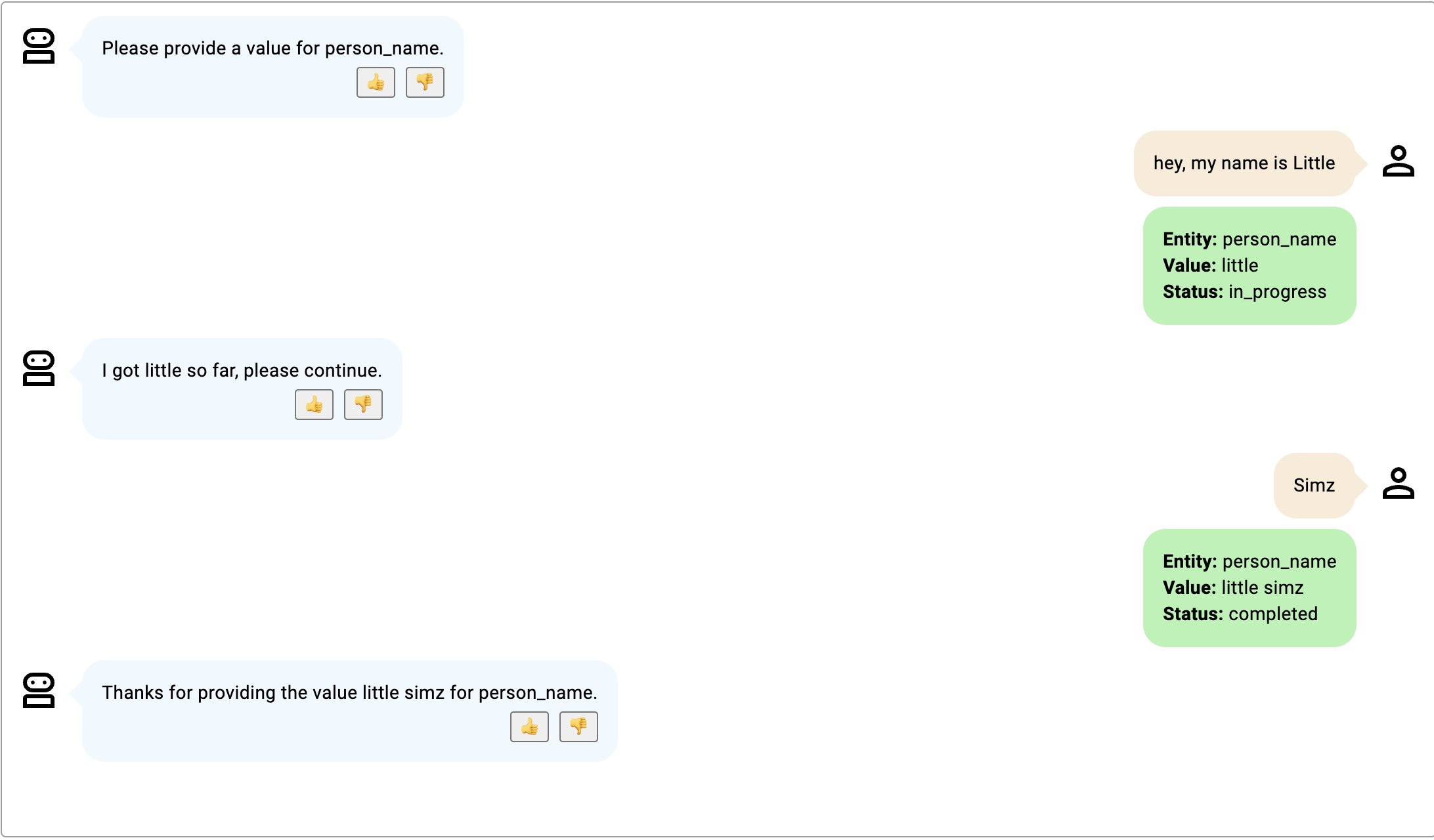
- 两个子实体同时提供,并且状态在第一轮之后变为完成。
点击图片放大。
- 状态保持在进行中,因为机器人参与者指定所提供的实体是中间名,未在描述中提及;机器人参与者提供的下一个实体被假定为姓氏,正如预期的那样。
点击图片放大。
- 虽然机器人参与者没有具体说明,并且“van der”应该被假定为姓氏,但可能不是,因为“van der”是一个常用的姓氏前缀,而不是实际的姓氏。
点击图片放大。
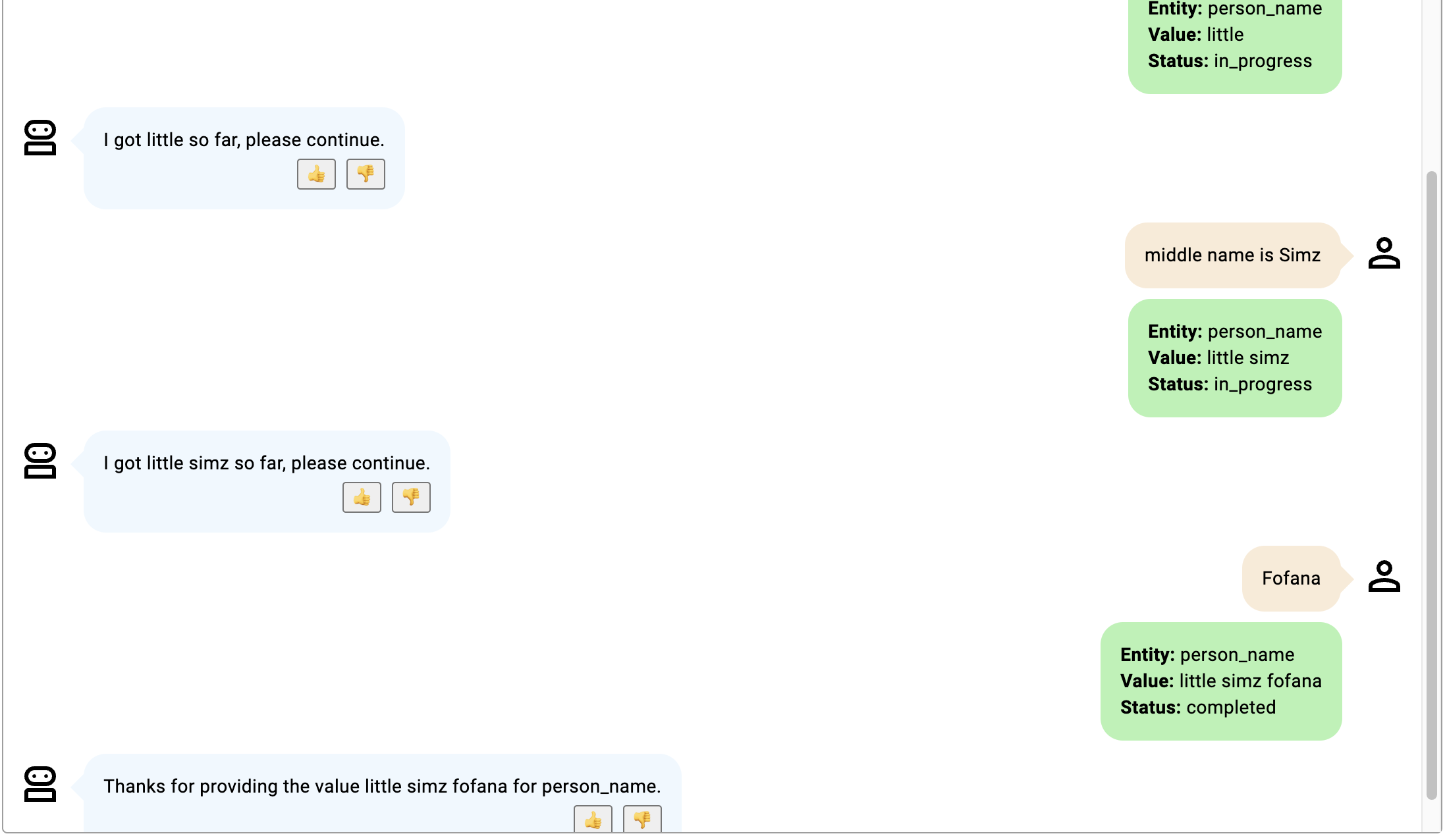
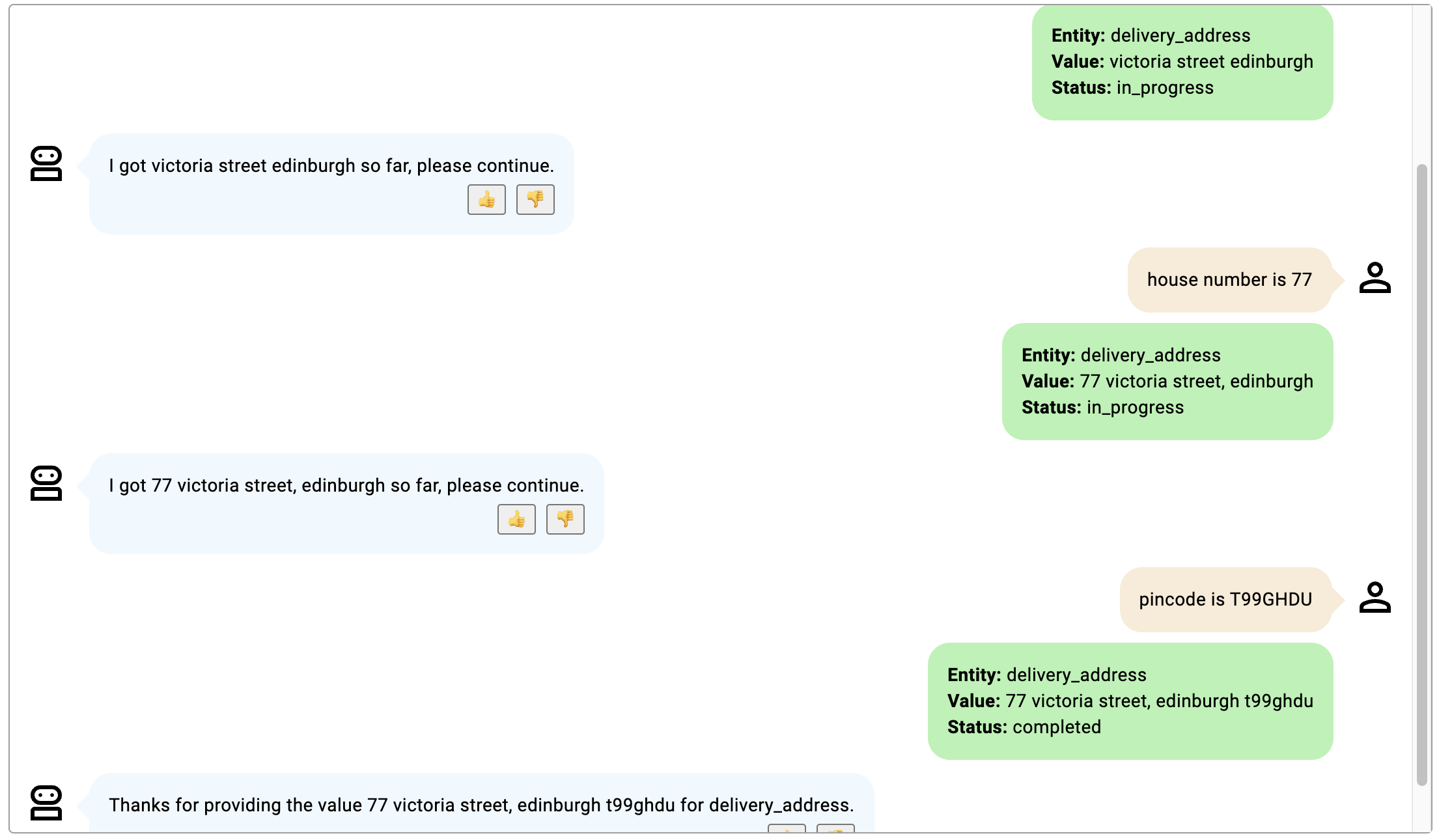
在这些例子中,插槽是 delivery_address,用于描述包括门牌号和 PIN 码的送货地址。
- 对话持续进行,直到提供门牌号和 PIN 码;在地址开头添加门牌号,在地址结尾添加 PIN 码。
点击图片放大。
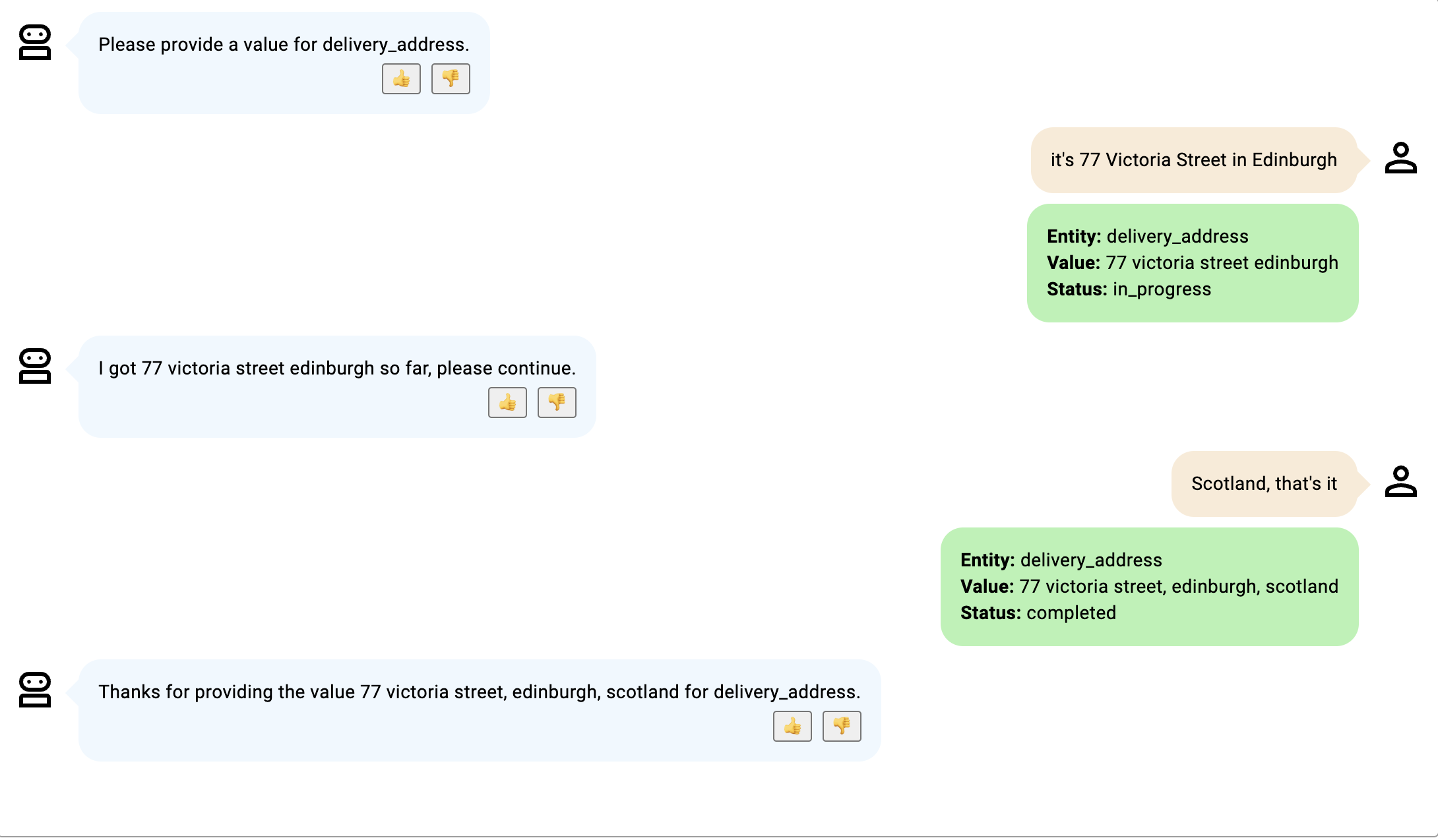
- 虽然没有提供 PIN 码,但由于机器人参与者表示他们已完成,因此状态变为完成。当参与者没有说“就是这样”时,不会出现此状态,并且只有提供 PIN 码时状态才会变为完成。
点击图片放大。
自由形式插槽示例:提前退出行为
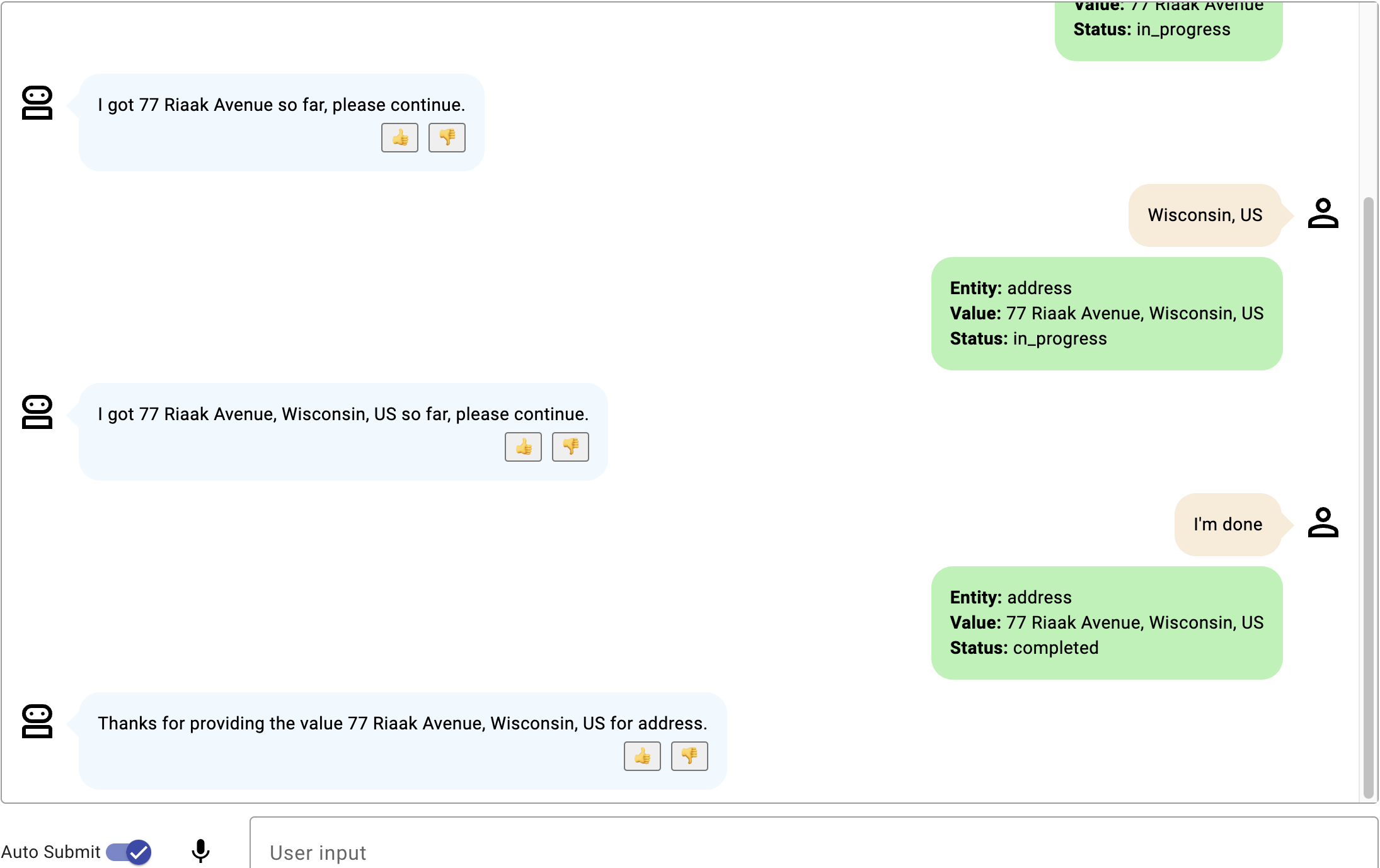
这些示例描述了 delivery_address 槽的提前退出行为场景,该槽描述了带有门牌号和 PIN 码的送货地址。
- 示例 1 提前退出示例
点击图片放大。
- 示例 2 提前退出示例。
点击图片放大。
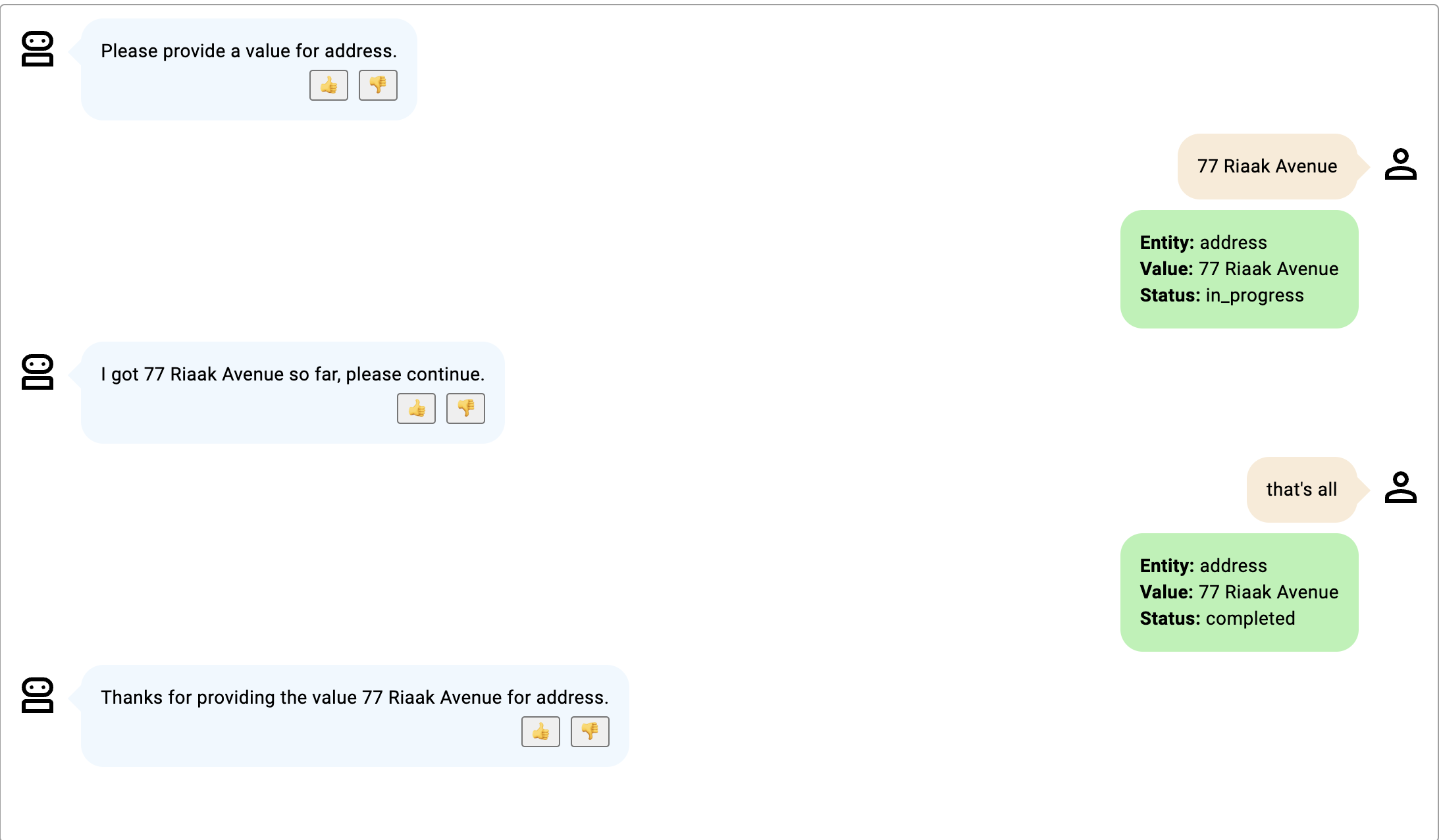
- 示例 3 提前退出示例。
点击图片放大。

- 示例 4 提前退出示例。
点击图片放大。

有关演示自由格式槽捕获工作原理的示例对话的信息,请参阅自由形式插槽捕获示例。
一般注意事项
- 槽提取的质量取决于语音通道中从音频到文本的转录的质量。随着转录错误的传播,“垃圾进,垃圾出”的概念在这里适用。
- 给客户的提示信息应该提到该实体可以一次或多次提供。